配置流程
1.安装PaddlePaddle 2.0
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
2.克隆PaddleOCR repo代码
git clone https://github.com/PaddlePaddle/PaddleOCR
如果因为网络问题无法pull成功,也可选择使用码云上的托管:
git clone https://gitee.com/paddlepaddle/PaddleOCR
**
3.安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt
4.下载inference模型
下载地址:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/quickstart.md

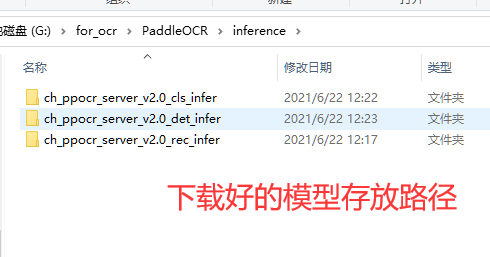
配置好的文件路径

应用
假设要识别下图中的文字
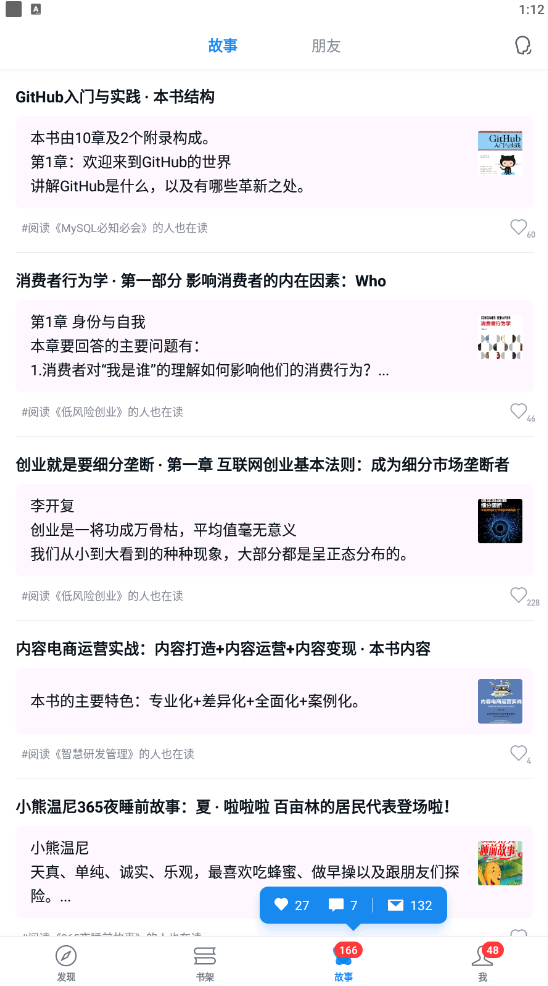
命令行操作方式为:
c:\python3\python.exe tools/infer/predict_system.py --image_dir="./doc/imgs/wechat_reading.png" --det_model_dir="./inference/ch_ppocr_server_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_server_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_server_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
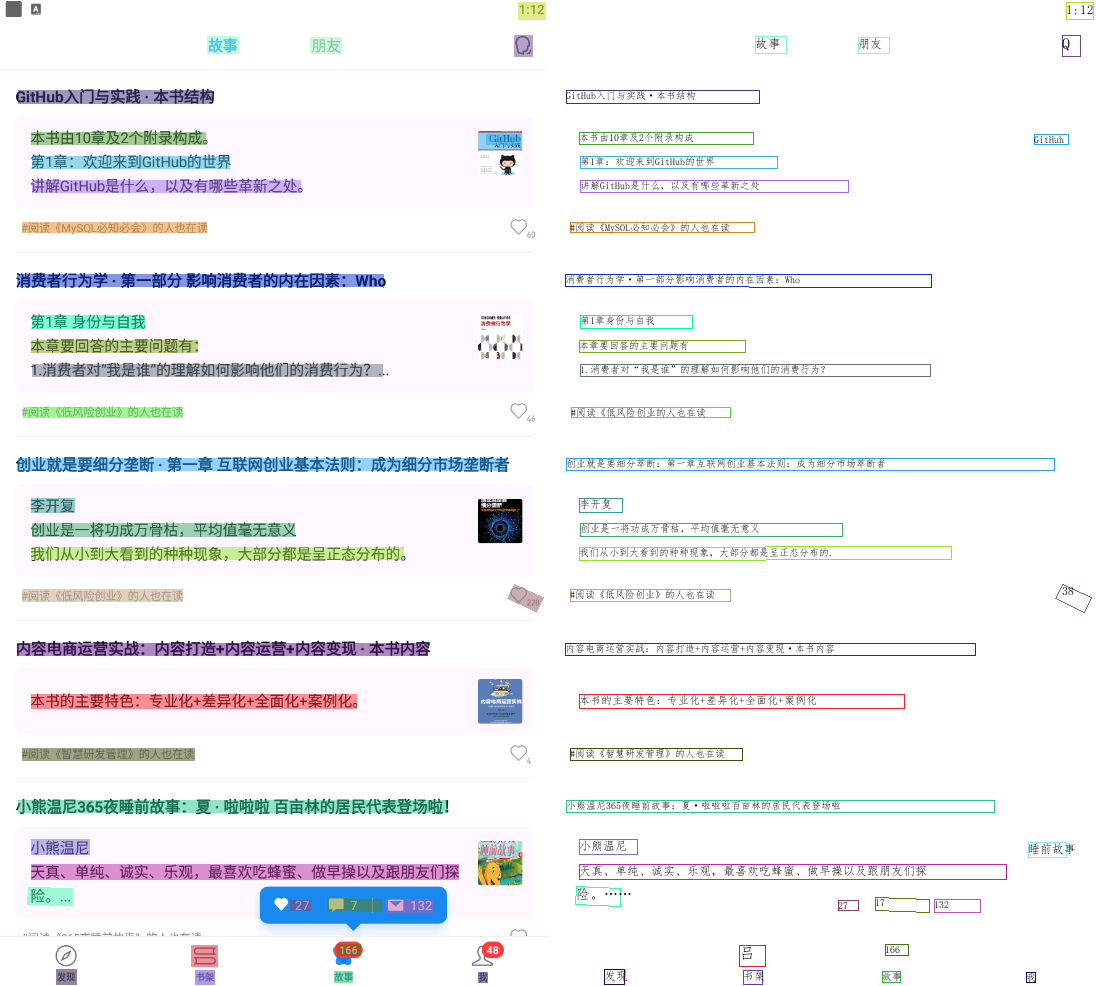
其实就是操作了git目录下的predict_system.py文件,将上面的图和训练模型作为输入,输出为命令行形式+图片形式(包含了所有文字位置、坐标的一幅图,见后)

可以看出,识别效果非常棒。
从识别输出的结果来看,如果需要按照下图的文字来做坐标识别,也是没问题的,唯一就是效率较慢,本机是i7的CPU进行计算,识别+制图的时间为22秒:
总结
一句话简介环境配置:python安装paddle,更新git库,并并下载paddle训练模型
今从晚向
这个人太懒什么东西都没留下
文章评论(0)